.webp)
AI-powered virtual screening services
Screen smarter.
Discover faster.
Turn billions of possibilities into breakthrough therapies with AI-powered virtual screening services that help deliver validated hits in hours, not months.
Start today

Why virtual screening
Virtual high-throughput screening (vHTS) complements early wet-lab assays by ranking millions of purchasable or make-on-demand compounds against a biological target in a matter of hours. Recent benchmarking shows that modern vHTS can
Recent benchmarking shows that modern vHTS can:

Raise hit rates two- to ten-fold versus random selection

Achieve AUC-ROC values of 0.80–0.95 in retrospective tests

Obtain an EF₁% of 10–50, meaning that the top 1% contains up to 50 х more true actives than a random sample

Compress months of experimental HTS into days of cloud computing time
What we deliver
Phase
Key activities
Your benefit
From target curation
to experimental validation,
we handle every step of your virtual screening campaign
Start todayCore approaches
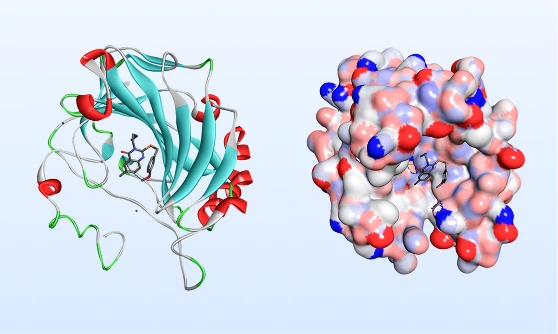
Structure-based screening
Flexible docking, induced-fit protocols, and MD-based pose refinement exploit X-ray, cryo-EM, or AlphaFold2 models.
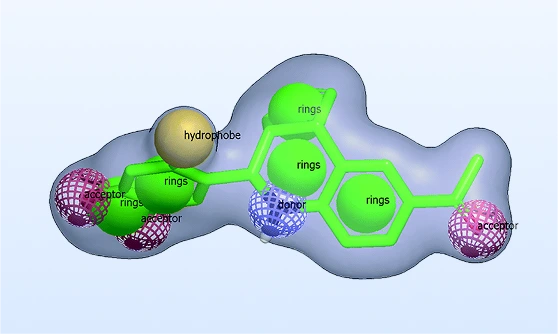
Ligand-based screening
Pharmacophore, 2-D/3-D similarity, field and shape overlays enrich for scaffold hops when the target structure is unknown.

Secure, elastic HPC
AWS Batch & Spot fleets spin up >50 k vCPUs or >5 k GPUs under ISO 27001-certified pipelines; all data are encrypted in transit and at rest.
AI enhancements

Reinforcement learning to focus on the most promising chemical regions in real time
.svg)
Various generative approaches to expand underexplored sub-pockets
.svg)
Neural Networks for rapid rescoring of data types like Graphs, Smiles, Descriptors, etc;
Metrics we track

Metric
Typical value
How we measure

AUC-ROC
Typical value0.80 – 0.95
How we measureFive-fold cross-validation on curated actives/decoys

EF₁ %
Typical value10 – 50
How we measureROC-E at 1 % false-positive rate

BEDROC(α=20)
Typical value0.35 – 0.70
How we measureEarly-recognition focus for projects with <1 % actives

Time-to-result
Typical value6–48 h for 100 M compounds
How we measure6–48 h for 100 M compounds


We are ready to tackle your
most challenging targets
Connect with our experts to design your optimal screening strategy
Start todayWhen to use our services

Rapid hit identification for novel or data-poor targets

Scaffold hopping to overcome IP or ADMET liabilities

Rescue of stalled HTS campaigns with low hit rates

Expansion around fragment or DEL hits

Exploration of covalent, allosteric, or cryptic pockets
Why partner with us?

Therapeutic depth
Our modeling scientists have delivered hits for kinases, GPCRs, ion channels, PPIs, and antiviral proteases.

Regulatory-grade documentation
Full audit trail, machine images, and parameter sets ready for IND dossiers.

Chemistry-centric filters
PAINS, REOS, colloidal aggregation, and synthetic accessibility scoring baked into every workflow.

Flexible engagement
Fee-for-service, FTE, or risk-sharing models; optional wet-lab follow-up in partner CRO network.
Start your journey to faster, smarter drug discovery today
Talk to usWhite-label R&D solutions under your brand
We offer ready-to-deploy, customizable AI pipelines — fully integrated with your existing systems and branded as your own.
Conquer R&D roadblocks with smart AI solutions
Book your free consultation now and speed up your R&D!
Start today
Explore our cases
Analytical platform for pharma
A global pharmaceutical company faced challenges with siloed data, limiting their ability to benefit from advanced analytics, machine learning, and AI. To address this, we developed a cloud-native enterprise data platform on AWS. The solution integrated diverse data streams into a scalable architecture with robust governance, automated pipelines, and advanced analytics capabilities.
The platform features a scalable data lake and warehouse with raw, transformed, and curated data layers for optimized access. Automated pipelines handle data ingestion from various sources, including pharmacovigilance, real-world evidence, and marketing. Advanced tools for data quality and governance ensured lineage tracking, quality testing, and security. These capabilities enable the company to perform predictive modeling, time series analysis, and other AI-powered analytics.
Technologies and tools:
AWS, Snowflake, Azure Devops, MSSQL, Airflow, PowerBI, Python, AWS S3, AWS Lambdas, AWS SageMaker, S3, Glue, CloudWatch, EC2, EKS, Python, Pandas, Numpy, PySpark, Scikit-Learn, PyTorch, MLFlow, statsmodels, scipy.

Extraction bioassay data from literature
Our client needed a solution to extract comprehensive bioassay data from literature since existing databases like ChEMBL and PubChem are valuable but incomplete. We developed a custom NLP pipeline to extract and store bioassay data, publication and publication metadata from literature (patent and scientific publications).
For this purpose, data extracted from the pipeline was combined with annotated datasets, ChEMBL bioassays, and PubChem bioassays to create comprehensive datasets for visualization and analysis. Furthermore, we built an intuitive dashboard with advanced filtering by various parameters (cell lines, assay types, species, targets, compounds, etc.) to enable fine-tuned search.
Technologies and tools:
Bigquery, Looker, Google cloud functions, Python, Pandas, Matplotlib, PostgreSQL, Django, DRF, Spacy, Pytorch Google cloud storage, Hugging Space, BERT
GenAI-powered solution for streamlined clinical documentation
Our client faced challenges in producing accurate and consistent documents from clinical and preclinical operations due to the complexity and time-consuming nature of the process. Their goal was to accelerate report writing, improve quality, and efficiently access relevant trial data. To address this, we developed a GenAI-based application leveraging Large Language Models (LLMs), Retrieval Augmented Generation (RAG), and classical NLP techniques.
This innovative software solution has improved the clinical documentation process, increased its efficiency and accuracy while ensuring consistency. The application includes advanced features like term recognition, which extracts key terms from diverse clinical documents, including scanned and handwritten PDFs, for efficient data management. It also integrates an AI-powered Q&A bot that provides instant answers to questions regarding clinical trial data, such as observations, demographics, and lab results. Additionally, a writing assistant streamlines report creation by pre-filling templates, performing consistency checks, offering structural and clarity recommendations, and automating reference generation.
Technologies and tools:
PyTorch, GPT-4o, Llama, BERT, Hugging Face, Scipy, Spacy, PandasAI, NLTK, Numpy, Scikit-Learn, Pandas, MLFlow, Redis, Docker, Docker Compose, PostgreSQL, Azure, BitBucket.
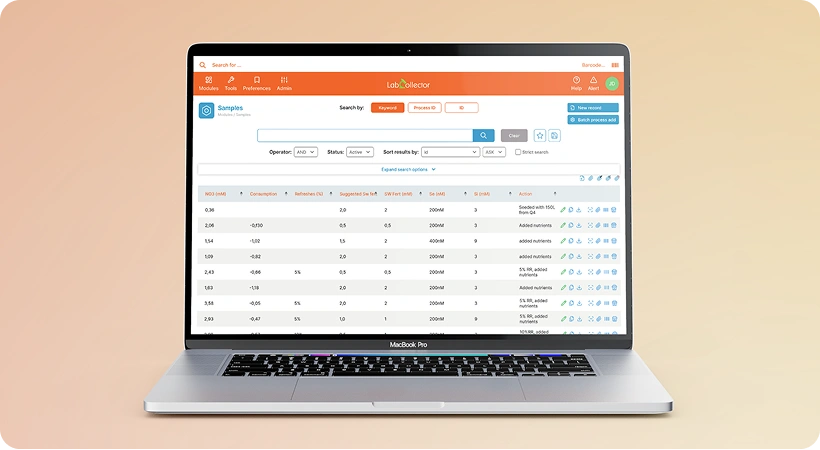
Lab data integration for enhanced EHR functionality
A healthcare facility, needed to integrate data from numerous disparate laboratory testing devices spread across different laboratories into its EHR system, providing healthcare providers with seamless access to results, including graphical outputs, for improved patient care. Collaborating with healthcare providers and lab personnel, we developed a platform that extracts data from lab equipment output files.
This innovative software solution has improved the clinical documentation process, increased its efficiency and accuracy while ensuring consistency. The application includes advanced features like term recognition, which extracts key terms from diverse clinical documents, including scanned and handwritten PDFs, for efficient data management. It also integrates an AI-powered Q&A bot that provides instant answers to questions regarding clinical trial data, such as observations, demographics, and lab results. Additionally, a writing assistant streamlines report creation by pre-filling templates, performing consistency checks, offering structural and clarity recommendations, and automating reference generation.
Technologies and tools:
Python, Java, MongoDB, MSSQL, Kafka, React, Pytorch, Numpy Pandas, Hugging Face, NLTK, spaCy, pyserial, plotly, stasmodels, SciPy
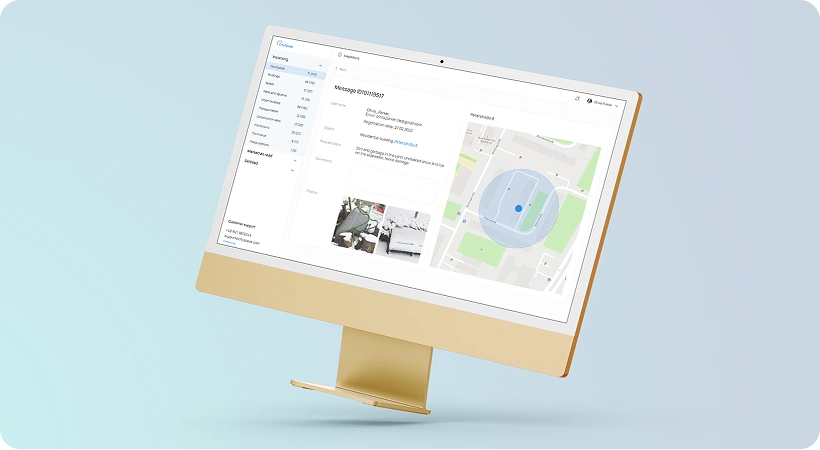
Circular economy data analytics
A manufacturing company sought to minimize waste and optimize resource utilization by transitioning to a circular economy model, but lacked the data insights to effectively manage material flows and identify improvement opportunities. For this purpose, we implemented an advanced data analytics platform that integrates real-time data across the entire product lifecycle, including material usage, production waste, manufacturing anomalies and errors, and product lifecycle stages.
The platform monitors material flows in real-time, detects inefficiencies and anomalies in manufacturing processes, and triggers alerts to personnel. It analyzes resource consumption patterns and suggests recovery strategies, provides end-to-end visibility into each product lifecycle stage from sourcing to disposal, and tracks key circular economy performance indicators to support continuous improvement towards sustainability goals.
Technologies and tools:
Python, Google BigQuery, Looker, AWS S3, MongoDB, Snowflake, IBM Watson Studio, Julia.
Link successfully copied to clipboard
Get in touch
Book a call or fill out the form and we’ll get back to you once we’ve processed your request.You can contact us using:

You can contact us using: